Ajax Editor
Ajax development
Ajax Editor
Ajax development
Bulk Copy Utility (BCP)As a DBA or System Administrator, you are often faced with the task of moving data from external sources to the Database Engine efficiently. BCP is one of tools enabling you to accomplish this task. The external data can come from a variety of sources, ranging from a Database Engine, to a database server from another vendor, to hardware devices (e.g., network controller), to applications such as Excel. Because each data source stores data in its native format, the Database Engine (or any native tool) cannot automatically interpret it for loading. The general strategy used to facilitate such data movement is to export the data into an intermediate format, commonly to a file, and then use the intermediate format to import the data into Database Engine. The Database Engine or tools can then read this file directly, transform its data to a representation that Database Engine understands, and then send the data over using Transfer Data Stream (TDS). Note, you need to send data over TDS when using tools, but not when Database Engine reads the file directly. TDS is an internal protocol used to communicate with Database Engine for sending or receiving both command and data. There are, however, some restrictions on how the data should be represented in the intermediate format before it can be imported into Database Engine. For example, when using Bulk Insert (a TSQL command), by default the data file must either be a TSV (tab-separated values) unless you are using a format file or have data represented in Database Engine's native format. These restrictions do not apply to client programs, but the downside is that you need to write a custom client program that interprets the data in the file before sending it to Database Engine. BCP is one such client application that ships with SQL Server, but it has restrictions similar to those listed previously for Bulk Insert. To be precise, actually it is the other way around. Bulk Insert was implemented much later than the BCP client application and was designed to be compatible with BCP (that is, to be able import the same data as BCP). In addition, there is another option for moving data: SQL Server Integrations Services (SSIS) can be used to import data into Database Engine. SSIS uses BCP or Bulk Insert at lower levels to import data and is geared toward more complex data transformation and workflow scenarios. Later in this chapter you will learn when to use BCP over other options available in SQL Server. In addition to using BCP to import data, you can use BCP to export data out of Database Engine and to generate a format file. You invoke BCP in a command shell window with parameters that specify the operation type: import/export, location of the data file, target or source table, an optional format file to describe the data, and various others. For example, BCP in represents the import operation, whereas BCP out represents an export operation. We will highlight some of the key parameters later in this chapter. The BCP client application has been available as part of SQL Server from the very beginning, starting with SQL Server 4.2. There have been some improvements over the releases, but mostly these improvements are to support the Database Engine functionality, such as new data types. However, there have been a few exceptions as follows:
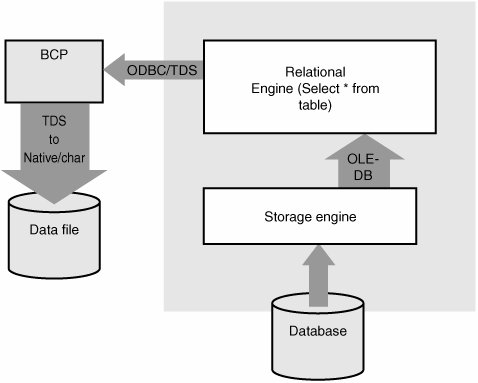
BCP ArchitectureAs mentioned earlier, the BCP client application is used to import/export data into/out of Database Engine. This section provides a high-level description of data flows into and out of Database Engine. For an import operation, BCP reads from a data file, optionally interprets the data using a format file, converts it into a Database Engine native format, and then calls ODBC (BCP 7.0 or later) or DBLIB (BCP 6.5) to send one or more data rows over TDS. On the server side, the bulk load module processes then generates an OLEDB rowset for the rows to be inserted and sends it to the relational engine to insert into the target table. Two special cases need to be mentioned here. First, the large objects (LOBs) import is optimized (using the API provided by Storage Engine, a lower layer of Database Engine) by directly storing the LOBs instead of copy, getting a pointer to the LOB data, and then inserting this pointer into the OLEDB rowset for the corresponding row/column. These steps are repeated for each LOB column in the target table. Second, if the target column type is XML, an XML validation component is called to validate and convert it into an internal format. After that it is processed the same way as other LOB data. Figure 5-6 illustrates the data flow from a data file to the target table in Database Engine. Figure 5-6. Data Flow during BCP import process.
The architecture during export operation (i.e., BCP out) is similar to its import counterpart except the data flow is reversed, as shown in Figure 5-7. The export operation retrieves data by executing a SELECT command on the target table and then writes the data into a file (in native or character mode, depending on command line options or as specified in the format file). Additionally, you can use BCP to generate a format file that describes output format (for export) of the data in the file or the input format (for import) of the data in the file. To export data out of Database Engine, you must have SELECT permission on the target table. Figure 5-7. Data Flow during BCP export process.
New in SQL2005 BCPAlthough BCP core functionality has not changed since previous releases, there are a few improvements as follows:
BCP Command SyntaxAt a high level, three components of a BCP command are of interest. The first component is the table. The table is either the target or the source of data to be transferred. The second component is the data file itself that, like the table, is either the source of or target for the data. The third component is the set of parameters that provide a wide range of choices such as error handling, locking, parallel BCP, handling of constraints/triggers, and how to interpret data in the file. Here is the full range of parameters available with BCP. Not surprising given the lineage of Database Engine (Sybase Adaptive Server was initially developed on the UNIX platform), you will notice the parameters have a UNIX flavor to maintain backward compatibility. bcp {[[database_name.][owner].]{table_name|view_name}|"query"} {in | out | queryout | format} data_file [-mmax_errors] [-fformat_file] [-x] [-eerr_file] [-Ffirst_row] [-Llast_row] [-bbatch_size] [-n] [-c] [-w] [-N] [-V (60 | 65 | 70 | 80)] [-6] [-q] [-C {ACP|OEM|RAW|code_page}] [-tfield_term] [-rrow_term] [-iinput_file] [-ooutput_file] [-apacket_size] [-Sserver_name[\instance_name]] [-Ulogin_id] [-Ppassword] [-T] [-v] [-R] [-k] [-E] [-h"hint [,...n]"] For full details on all of these parameters please refer to product documentation (SQL Server Books Online), but a few key parameters are highlighted here:
BCP Usage ScenariosThe bcp command provides a huge number of command line options that enable many scenarios. This section covers a few representative scenarios. Most of the scenarios are based on the following Employee table. This table has one unique index on EmpID and one constraint that checks that all employees are older than 18. Employee (EmpID varchar(10) unique,
EmpAge int check (EmpAge > 18),
EmpDept varchar(100),
EmpSalary decimal)
Simple Export and ImportSuppose this table exists in SQL Server 2000 and you want to transfer this table to SQL Server 2005. There are multiple ways to accomplish this. You can, for example, use backup and restore to move the entire database to a SQL Server 2005 instance and then extract the Employee table. However, the downside of this is that you are forced to copy the whole database, and it requires a higher level of privileges. This can be particularly painful if the Employee table is a small fraction of the overall database. Alternatively, you can use Linked Server functionality to directly access the Employee table in a SQL Server 2000 instance and move it to a SQL Server 2005 instance. However, in both of these cases the data transfer is not fully optimized (e.g., the insert into the target table is fully logged). On the other hand, the BCP client application provides a much simpler and more efficient way to transfer this data using the following steps:
Error HandlingThe preceding scenario assumed that everything was correct with no chance of error. However, in real-life situations, the System Administrators and DBAs have a small window in which to import data and limited capacity to recover should anything go wrong. Some common errors that can cause failure during an import operation are
BCP provides a few parameters to handle errors like these, as follows: bcp <dbname>..Employee in <datafile> S<instance-name> -c T m 100 e <error-file> By using the m parameter, you are instructing BCP to ignore the first 100 format errors in data representation. By default, BCP ignores the first 10 errors. You can move the rows that have format errors into a separate error file for analysis by using the e option. Similarly, by not specifying the h option, you are, in fact, disabling the constraints checks. If you enable the constraint checks, and any row violates the constraint, the bcp command is terminated and all newly inserted rows are removed. If this or any other error happens toward the end of a large load, it can result in wasted resources of Database Engine and time. To get around this, you can use the b parameter that lets you commit a set of rows (i.e., a batch) at a time. This way, if a subsequent batch fails because of some errors, the SysAdmin or DBA needs to reload data from only that batch, eliminating the need to reload the data that was already successfully imported. The following bcp command specifies a batch size of 1000. bcp <dbname>..Employee in <datafile> S<instance-name> -c T m 100e <error-file> Generating and Using Format FilesSo far, we have only considered the case where both the source and target tables had identical schema. Another common case involves fields in a data file that do not match with the target table, neither in number of columns nor in ordering. To import this data, you need a way to map data fields in the file to the corresponding columns in the target table. Format files can be used to provide this mapping. Like TSQL Insert, any column that is not mapped must have a default or must allow NULLs for the import operation to succeed. You can generate this format file as part of exporting data, or you can create it explicitly through the BCP program. Let us consider a new target table, NewEmployee, with the following schema (note that it does not have an EmpDept column): NewEmployee (EmpID varchar(10) unique,
EmpAge int check (EmpAge > 18),
EmpSalary decimal)
Assume that you need to import data that was generated during an export from the Employee table into this new target. To do this, the first step is to generate an XML format file that uses the source table as follows: bcp <dbname>..employee format nul -f employee-fmt-xml.xml -x -c S<instance-name> T
<?xml version="1.0"?>
<BCPFORMAT
xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="\t"
MAX_LENGTH="10"
COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\t"
MAX_LENGTH="12"/>
<FIELD ID="3" xsi:type="CharTerm" TERMINATOR="\t"
MAX_LENGTH="100"
COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
<FIELD ID="4" xsi:type="CharTerm" TERMINATOR="\r\n"
MAX_LENGTH="41"/>
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="EmpID" xsi:type="SQLVARYCHAR"/>
<COLUMN SOURCE="2" NAME="EmpAge" xsi:type="SQLINT"/>
<COLUMN SOURCE="3" NAME="EmpDept" xsi:type="SQLVARYCHAR"/>
<COLUMN SOURCE="4" NAME="EmpSalary" xsi:type="SQLDECIMAL"
PRECISION="18" SCALE="0"/>
</ROW>
</BCPFORMAT>
Because the new target table does not have EmpDept, the above format file needs to be modified to match the target table. To do this, the column row associated with EmpDept is removed and the third column is mapped to the fourth field in the data file. <?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/
bulkload/format"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="\t"
MAX_LENGTH="10"
COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\t"
MAX_LENGTH="12"/>
<FIELD ID="3" xsi:type="CharTerm" TERMINATOR="\t"
MAX_LENGTH="100"
COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
<FIELD ID="4" xsi:type="CharTerm" TERMINATOR="\r\n"
MAX_LENGTH="41"/>
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="EmpID" xsi:type="SQLVARYCHAR"/>
<COLUMN SOURCE="2" NAME="EmpAge" xsi:type="SQLINT"/>
<COLUMN SOURCE="4" NAME="EmpSalary" xsi:type="SQLDECIMAL"
PRECISION="18" SCALE="0"/>
</ROW>
</BCPFORMAT>
Now you can use the following command to import the data: bcp <dbname>.NewEmployee in <datafile> f <formatfile> S<instance-name> -n T Note we could have done the same using the non-XML format file as follows: 9.0 4 1 SQLCHAR 0 10 "\t" 1 EmpID SQL_Latin1_General_CP1_CI_AS 2 SQLCHAR 0 12 "\t" 2 EmpAge "" 3 SQLCHAR 0 100 "\t" 0 EmpDept SQL_Latin1_General_CP1_CI_AS 4 SQLCHAR 0 41 "\r\n" 3 EmpSalary "" If you compare both format files, a couple of things stand out. First, the XML-based format file is much easier to understand. Second, it explicitly defines the target column types. Target column types are useful, not as much in the context of BCP, but when used with BULK INSERT and OPENROWSET. There is, however, one restriction with XML-based format files. Unlike non-XML format files, you cannot use them to skip columns in the target table. You can get around this issue by creating a view on the target table and map the columns as needed and then import the data into the view. Optimized Bulk ImportSo far we have focused only on functional scenarios. One of the main benefits of BCP is that it can be used to efficiently load data into Database Engine. The optimizations available during bulk import are
In the simplest case, you can import data into a heap (a table with no indexes) or into an empty table if there are indexes using optimizations listed above; however there are a few exceptions. For heaps, because there is no index, the optimization related to sorting is irrelevant. For the empty table with an index, you cannot do parallel load with optimized logging at the same time. In the case of an index, you have to choose whether you want optimized logging or parallel load. Another interesting point is that for an index, the optimized logging is available only when the target index is empty. If you want to import data in multiple batches, then by definition, the target index is not empty after the completion of the first successful batch. And finally, to be able to do optimized logging, your database must be configured for the "Bulk Logged" or "Simple" recovery model. As you can see, identifying cases for bulk optimizations can be tedious. Table 5-1 lists these cases, assuming there is no lock escalation.
You should note a few points in this table. First, the parallel Bulk Load is available only when the locking mode is BU lock. BU lock is a special table-level lock that enables multiple BCP threads to load data concurrently, but conflicts with all other locks. Second, you must specify the TABLOCK hint to be able to do optimized bulk logging. It is a necessary but not sufficient condition. The following bcp command imports data into the target table Employee with the preceding optimizations, assuming the table was empty to start with: bcp <dbname>..employee in empoyee-dat-c.dat -SSUNILA2\BLD1313 -c -T -h "TABLOCK" Because the employee table in this example has an implicit index (because of the unique constraint on the column EmpID), you cannot execute multiple BCP threads concurrently. One good strategy under this situation is to drop the index(es) so that the target table becomes a heap, use multiple BCPs to load the data in parallel, and then finally recreate the index. Because the target table was empty to start with, there is no additional cost to drop the index and then re-create it after the data has been imported. This is, however, not as black and white when you want to load incremental data into a target table with multiple indexes with a large number of existing rows. You need to weigh the cost of dropping and re-creating indexes and the availability requirements of the table against the benefits from doing an optimized bulk import with BCP. There is another choice available in SQL Server 2005 that uses table partitioning. If applicable, you can load incremental data into an empty heap by using bulk optimizations, creating required indexes, and then snapping in the table as a new partition into a partitioned table. For details on partitioned tables, please refer to SQL Server Books Online. |
Ajax Editor
Ajax development